






| Gene | Smallest unit of information |
| DNA / Chromosome / Genome | Sequence of genes |
| Population | Collection of individual DNAs |
| Generation | A new population of evolved DNA |
| Fitness | The score or quality of a DNA |
| Fitness Function | Objective function which calculates the score of a DNA |
| Selection | A strategy to select parent DNAs for reproduction based on their fitness |
| Recombination / Crossover | A strategy to copy genes from parent DNAs to create new child DNAs |
| Mutation | A (random) change of one or more genes in a DNA |
| Gene | Location of a city |
| DNA / Chromosome / Genome | A sequence of city locations = route |
| Population | Collection of individual routes |
| Generation | A new collection of evolved routes |
| Fitness | The total length of a route |
| Fitness Function | Adds up the distances between every pair of cities in the route |
| Selection | A strategy to select routes based on their fitness to create new routes |
| Recombination / Crossover | A strategy to copy locations from parent routes to build new child routes |
| Mutation | Swapping one or more locations in a route |



// The algorithm is composed of two classes. A reusable GeneticAlgorithm
// class and a DNA class which implements a specific problem:
//
// - The GeneticAlgorithm class guides the evolution process of DNAs.
// It manages the DNAs of the current population and next generation
// and implements a strategy to select parent DNAs for reproduction.
// It can be used for different problems without modification.
//
// - A DNA class implements a particular problem to be solved by a
// Genetic Algorithm. The class manages its own reproduction with
// recombination / crossover, its mutation and fitness evaluation.
// A DNA class is not very reusable and must be customized for each
// problem. In this case a Travelling Salesman Problem is
// implemented as a DNA_TSP class.
//
// There is no abstract base class for a DNA to inherit from. A user has to
// implement a DNA class with its particular methods and inject it into a
// GeneticAlgorithm by using templates. With this 'duck typing' approach all
// types will be figured out at compile time and not at runtime.
#include <memory>
using std::unique_ptr;
#include <iostream>
using std::cout;
#include <iomanip>
using std::left;
using std::setw;
using std::fixed;
using std::setprecision;
#include "genetic_agorithm.hpp"
#include "dna_tsp.hpp"
int main()
{
// The Genetic Algorithm will be initialized with a Travelling Salesman
// Problem. The total length of a route through many locations should
// be minimized.
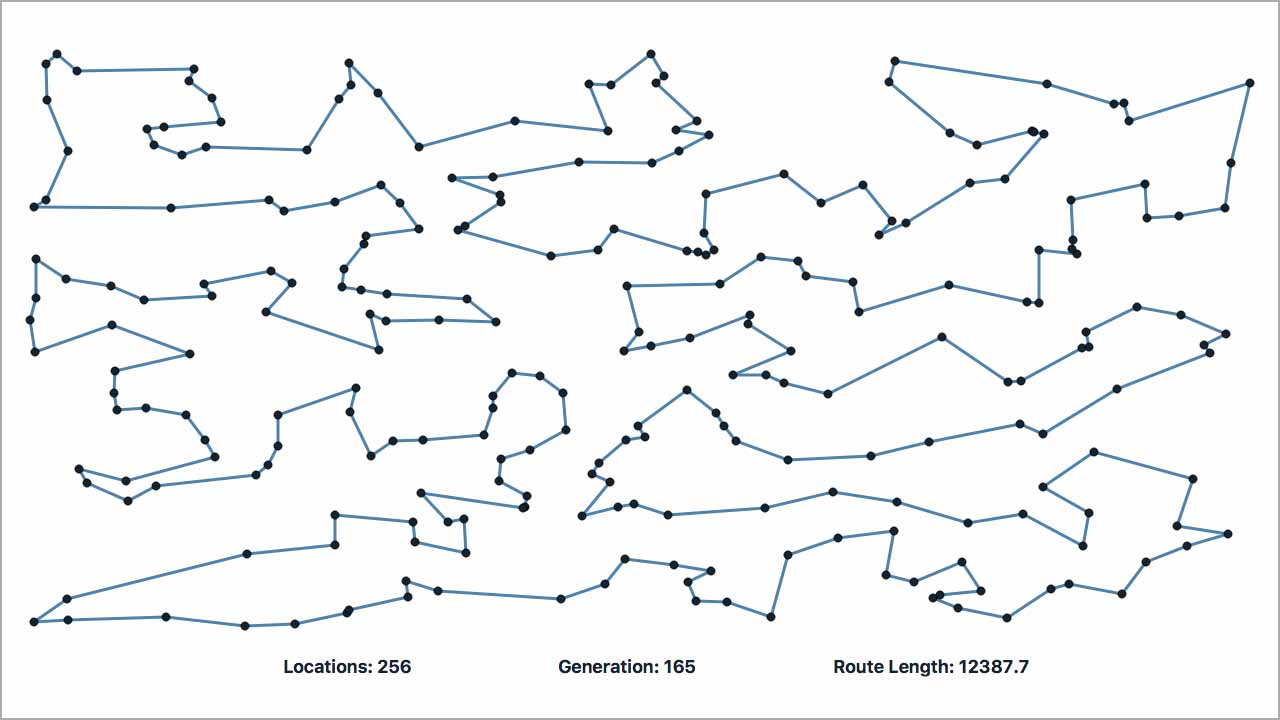
// The 'Berlin52' data set consists of 52 route locations.
const vector<double> routeLocationsX =
{ 565.0, 25.0, 345.0, 945.0, 845.0, 880.0, 25.0, 525.0, 580.0, 650.0,
1605.0, 1220.0, 1465.0, 1530.0, 845.0, 725.0, 145.0, 415.0, 510.0, 560.0,
300.0, 520.0, 480.0, 835.0, 975.0, 1215.0, 1320.0, 1250.0, 660.0, 410.0,
420.0, 575.0, 1150.0, 700.0, 685.0, 685.0, 770.0, 795.0, 720.0, 760.0,
475.0, 95.0, 875.0, 700.0, 555.0, 830.0, 1170.0, 830.0, 605.0, 595.0,
1340.0, 1740.0 };
const vector<double> routeLocationsY =
{ 575.0, 185.0, 750.0, 685.0, 655.0, 660.0, 230.0, 1000.0, 1175.0, 1130.0,
620.0, 580.0, 200.0, 5.0, 680.0, 370.0, 665.0, 635.0, 875.0, 365.0,
465.0, 585.0, 415.0, 625.0, 580.0, 245.0, 315.0, 400.0, 180.0, 250.0,
555.0, 665.0, 1160.0, 580.0, 595.0, 610.0, 610.0, 645.0, 635.0, 650.0,
960.0, 260.0, 920.0, 500.0, 815.0, 485.0, 65.0, 610.0, 625.0, 360.0,
725.0, 245.0 };
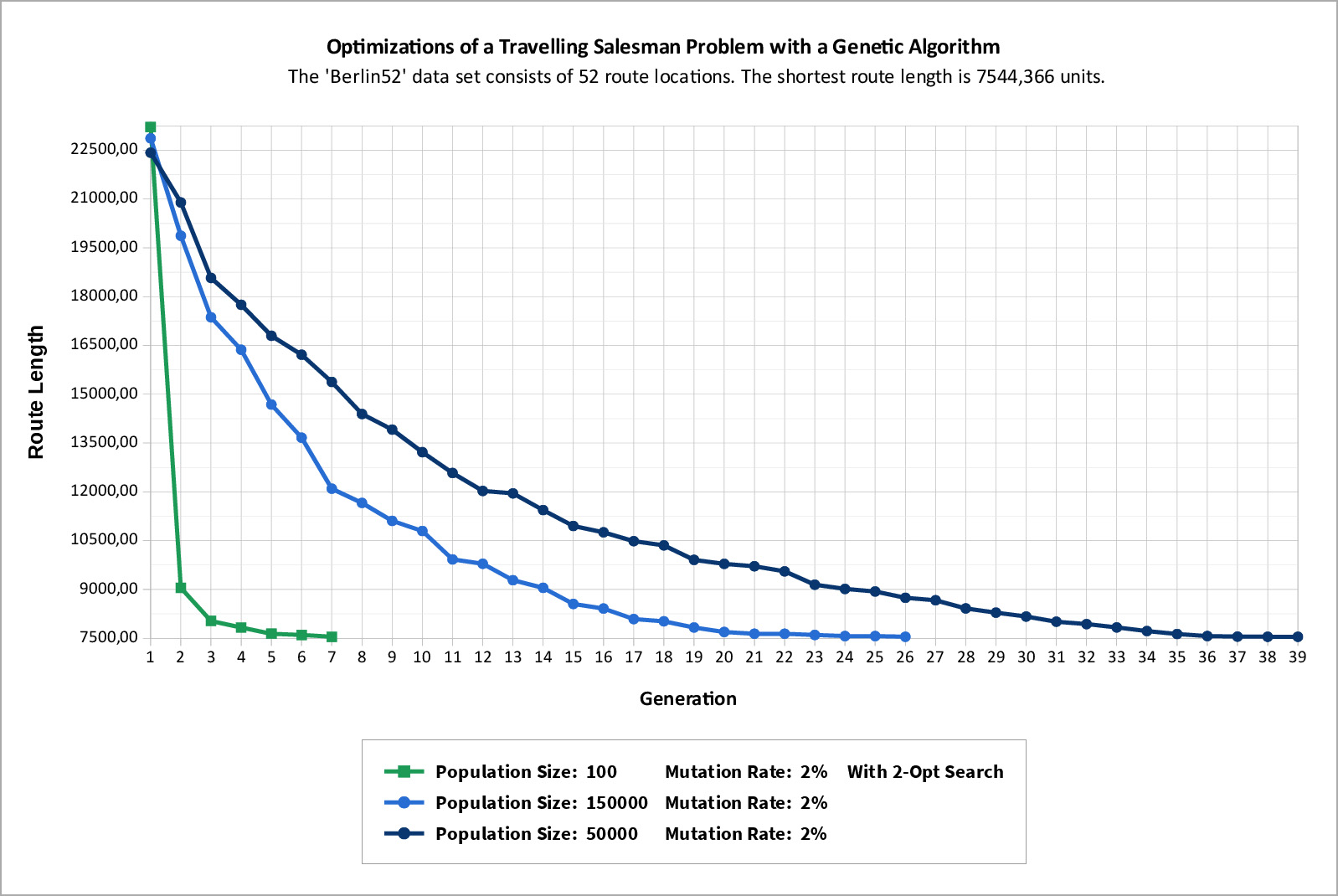
// The correct answer for the 'Berlin52' data set is known, so this specific
// Travelling Salesman Problem can be used to evaluate the performance of
// the Genetic Algorithm. The shortest route (global optimal solution) is:
//
// { 0, 48, 31, 44, 18, 40, 7, 8, 9, 42, 32, 50, 10, 51, 13, 12, 46, 25, 26,
// 27, 11, 24, 3, 5, 14, 4, 23, 47, 37, 36, 39, 38, 35, 34, 33, 43, 45, 15,
// 28, 49, 19, 22, 29, 1, 6, 41, 20, 16, 2, 17, 30, 21, (0) } Length: 7544.366
//
// The route is a loop of location indices and can be read in
// forward or backward direction.
const double optimalRouteLength = 7544.366; // 0.0 if the route length is unknown
auto initialDNA = DNA_TSP(routeLocationsX, routeLocationsY, optimalRouteLength);
initialDNA.initGenesWithRandomValues();
const size_t populationSize = 100;
const double percentOfBestCanReproduce = 50.0;
const double recombinationProbability = 0.9; // 90%
const double mutationProbability = 0.02; // 2%
auto ga = unique_ptr< GeneticAlgorithm<DNA_TSP> >(
new GeneticAlgorithm<DNA_TSP> (
&initialDNA,
GeneticAlgorithmObjective::Minimization,
populationSize,
percentOfBestCanReproduce,
recombinationProbability,
mutationProbability) );
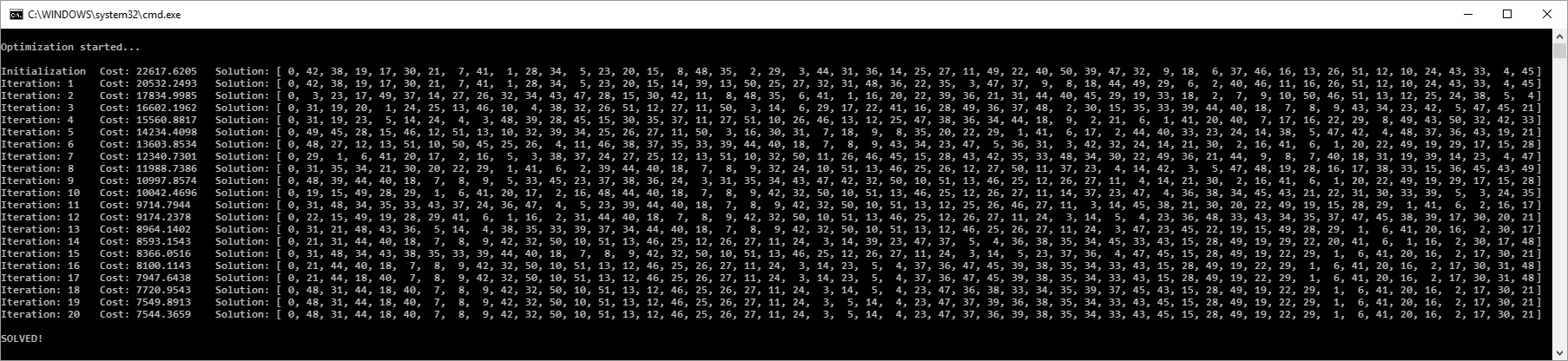
cout << "\nOPTIMIZATION STARTED ...\n\n";
cout << "Population size: " << ga->getPopulationSize() << "\n";
cout << "Percent Of best DNA can reproduce: " << percentOfBestCanReproduce << "%\n";
cout << "Recombination probability: " << recombinationProbability * 100.0 << "%\n";
cout << "Mutation probability: " << mutationProbability * 100.0 << "%\n\n";
auto printGeneration = [&]()
{
cout << "Generation: "
<< left << setw(5) << ga->getNumEvolvedGenerations()
<< " Best Fitness: "
<< left << setw(10) << fixed
<< setprecision(4) << ga->getBestDNAfitness() << "\n";
};
printGeneration();
while (!ga->isProblemSolved())
{
ga->evolveNextGeneration();
printGeneration();
}
if (ga->isProblemSolved())
{
cout << "\nSOLVED!\n\n";
cout << "Number of evolved generations: " << ga->getNumEvolvedGenerations() << "\n";
cout << "Number of improved generations: " << ga->getNumGenerationImprovements() << "\n";
cout << "Number of fitness evaluations: " << ga->getNumFitnessEvaluations() << "\n";
cout << "Number of fitness improvements: " << ga->getNumFitnessImprovements() << "\n";
if (ga->getNumEvolvedGenerations())
{
const auto fitnessImprovementsPerGeneration =
static_cast<double>(ga->getNumFitnessImprovements()) /
static_cast<double>(ga->getNumEvolvedGenerations());
cout << "Number of fitness improvements per generation: "
<< fitnessImprovementsPerGeneration << "\n\n\n";
}
}
return 0;
}
// Functions for the creation of (pseudo) random numbers.
//
// A Mersenne Twister is used as a high quality (pseudo) random number
// generator. It is slower than simply calling the rand() function but it will
// create better random numbers with a very good (uniform) distribution and
// is thread safe.
//
// A random number generator instance will be created once for every thread,
// so it must not be locked / synced, which will result in a better performance.
//
// The system time & thread id will be used to create an initial random seed.
// When the system clock is called by multiple threads at nearly the same time
// it might return the same value. A hash of the thread id will be combined
// with the current time to create a unique random seed for every thread.
#pragma once
#include <iostream>
#include <string>
#include <random>
using std::mt19937;
using std::uniform_int_distribution;
using std::uniform_real_distribution;
using std::bernoulli_distribution;
#include <chrono>
#include <thread>
using std::thread;
#include <functional>
using std::hash;
#include <memory>
using std::unique_ptr;
// By defining a fixed seed value the random number generator can be
// forced to produce the exact same set of pseudo random numbers all
// the time. This can be temporarily useful for general debugging or
// performance optimizations of algorithms.
// #define USE_FIXED_SEED
inline unsigned int getRandomSeed()
{
#ifdef USE_FIXED_SEED
return 123456789;
#else
// Seed = Randomized variable address per thread (by os) + thread id + time
const auto localVariable = 0;
const auto randomMemoryAddress = reinterpret_cast<size_t>(&localVariable);
const auto time = static_cast<size_t>(
std::chrono::high_resolution_clock::now().time_since_epoch().count() );
const size_t thread_id = hash<thread::id>()(std::this_thread::get_id());
return static_cast<unsigned int>(randomMemoryAddress + thread_id + time);
#endif
}
inline mt19937* getMersenneTwisterEngine()
{
static thread_local unique_ptr<mt19937> generator_owner;
static thread_local mt19937* generator = nullptr;
if (!generator)
{
generator_owner.reset(new mt19937(getRandomSeed()));
generator = generator_owner.get();
}
return generator;
}
template<typename T> T
inline getRandomIntegerInRange(T minInclusive, T maxInclusive)
{
auto generator = getMersenneTwisterEngine();
uniform_int_distribution<T> distribution(minInclusive, maxInclusive);
return distribution(*generator);
}
template<typename T> T
inline getRandomRealInRange(T minInclusive, T maxInclusive)
{
auto generator = getMersenneTwisterEngine();
uniform_real_distribution<T> distribution(minInclusive, maxInclusive);
return distribution(*generator);
}
inline bool getRandomTrueWithProbability(double probability)
{
auto generator = getMersenneTwisterEngine();
std::bernoulli_distribution distribution(probability);
return distribution(*generator);
}
// This Genetic Algorithm class guides the evolution process of DNAs.
// It manages the DNAs of the current population and next generation
// and implements a strategy to select parent DNAs for reproduction.
// It can be used for different problems without modification.
#pragma once
#include <iostream>
using std::cout;
#include <string>
using std::string;
#include <vector>
using std::vector;
#include <memory>
using std::unique_ptr;
#include <utility>
using std::move;
using std::pair;
using std::make_pair;
#include <limits>
#include <algorithm>
#include "randnumgen.hpp"
// The objective of an optimization algorithm is to minimize or maximize
// the output value of an objective function. The algorithm has to
// systematically pick or create input variables (solutions) for the
// objective function until a sufficient or optimal solution is found.
//
// When the output value of an objective function should be minimized,
// it is also called a 'loss function' or 'cost function'. If the output
// value should be maximized, the objective function is often called a
// 'reward function' or a 'fitness function' in the case of
// a Genetic Algorithm.
enum GeneticAlgorithmObjective { Minimization, Maximization };
template<typename DNA>
class GeneticAlgorithm
{
public:
GeneticAlgorithm(
const DNA* initialDNA,
GeneticAlgorithmObjective objective,
size_t populationSize,
double percentOfBestCanReproduce,
double recombinationProbability,
double mutationProbability);
void evolveNextGeneration();
GeneticAlgorithmObjective getObjective() const;
size_t getPopulationSize() const;
size_t getNumEvolvedGenerations() const;
size_t getNumFitnessEvaluations() const;
size_t getNumFitnessImprovements() const;
size_t getNumGenerationImprovements() const;
double getBestDNAfitness() const;
string getBestDNAstring() const;
bool isProblemSolved() const;
private:
inline void createInitialPopulation();
inline void calcAllFitnessValues();
inline void createSelectionPool();
inline void selectParentsFromPool();
private:
const DNA* _initialDNA;
GeneticAlgorithmObjective _objective;
size_t _populationSize;
size_t _halfPopulationSize;
double _percentOfBestCanReproduce;
double _recombinationProbability;
double _mutationProbability;
vector<unique_ptr<DNA>> _population;
vector<unique_ptr<DNA>> _nextGeneration;
vector<size_t> _selectionPool;
DNA* _parentDNA1;
DNA* _parentDNA2;
DNA* _bestDNA;
size_t _numEvolvedGenerations;
size_t _numFitnessEvaluations;
size_t _numFitnessImprovements;
size_t _numGenerationImprovements;
};
// ----------------------------------------------------------------------------
template<typename DNA>
GeneticAlgorithm<DNA>::GeneticAlgorithm(
const DNA* initialDNA,
GeneticAlgorithmObjective objective,
size_t populationSize,
double percentOfBestCanReproduce,
double recombinationProbability,
double mutationProbability)
{
_initialDNA = initialDNA;
_objective = objective;
// Ensure a minimum and even population size
_populationSize = std::max<size_t>(4, populationSize);
if (_populationSize % 2 != 0)
_populationSize++;
_halfPopulationSize = _populationSize / 2;
if (_populationSize != populationSize)
cout << "Adjusted population size to an even size: "
<< _populationSize << "\n";
_percentOfBestCanReproduce = percentOfBestCanReproduce;
_recombinationProbability = recombinationProbability;
_mutationProbability = mutationProbability;
_selectionPool.reserve(_populationSize);
_parentDNA1 = nullptr;
_parentDNA2 = nullptr;
_bestDNA = nullptr;
_numEvolvedGenerations = 0;
_numFitnessEvaluations = 0;
_numFitnessImprovements = 0;
_numGenerationImprovements = 0;
createInitialPopulation();
}
template<typename DNA>
GeneticAlgorithmObjective GeneticAlgorithm<DNA>::getObjective() const
{
return _objective;
}
template<typename DNA>
size_t GeneticAlgorithm<DNA>::getPopulationSize() const
{
return _populationSize;
}
template<typename DNA>
size_t GeneticAlgorithm<DNA>::getNumEvolvedGenerations() const
{
return _numEvolvedGenerations;
}
template<typename DNA>
size_t GeneticAlgorithm<DNA>::getNumFitnessEvaluations() const
{
return _numFitnessEvaluations;
}
template<typename DNA>
size_t GeneticAlgorithm<DNA>::getNumFitnessImprovements() const
{
return _numFitnessImprovements;
}
template<typename DNA>
size_t GeneticAlgorithm<DNA>::getNumGenerationImprovements() const
{
return _numGenerationImprovements;
}
template<typename DNA>
double GeneticAlgorithm<DNA>::getBestDNAfitness() const
{
return _bestDNA->getFitness();
}
template<typename DNA>
string GeneticAlgorithm<DNA>::getBestDNAstring() const
{
return _bestDNA->toString();
}
template<typename DNA>
bool GeneticAlgorithm<DNA>::isProblemSolved() const
{
return _bestDNA->isSolved();
}
template<typename DNA>
inline void GeneticAlgorithm<DNA>::createInitialPopulation()
{
// INITIALIZATION (See Tutorial)
_population.resize(_populationSize);
_nextGeneration.resize(_populationSize);
for (size_t iDNA = 0; iDNA < _populationSize; iDNA++)
{
_population[iDNA] = unique_ptr<DNA>( new DNA(*_initialDNA) );
_population[iDNA]->initGenesWithRandomValues();
_nextGeneration[iDNA] = unique_ptr<DNA>( new DNA(*_initialDNA) );
_nextGeneration[iDNA]->initGenesWithRandomValues();
}
// FITNESS EVALUATION (See Tutorial)
calcAllFitnessValues();
_numEvolvedGenerations = 1;
}
template<typename DNA>
inline void GeneticAlgorithm<DNA>::calcAllFitnessValues()
{
double minFitness = std::numeric_limits<double>::max();
double maxFitness = std::numeric_limits<double>::min();
double fitness = 0.0;
if (_objective == GeneticAlgorithmObjective::Minimization)
{
for (size_t iDNA = 0; iDNA < _populationSize; iDNA++)
{
fitness = _population[iDNA]->calcFitness();
_numFitnessEvaluations++;
if (fitness < minFitness)
{
minFitness = fitness;
_bestDNA = _population[iDNA].get();
_numFitnessImprovements++;
}
}
}
else if (_objective == GeneticAlgorithmObjective::Maximization)
{
for (size_t iDNA = 0; iDNA < _populationSize; iDNA++)
{
fitness = _population[iDNA]->calcFitness();
_numFitnessEvaluations++;
if (fitness > maxFitness)
{
maxFitness = fitness;
_bestDNA = _population[iDNA].get();
_numFitnessImprovements++;
}
}
}
}
template<typename DNA>
void GeneticAlgorithm<DNA>::evolveNextGeneration()
{
// PRE-SELECTION
// Potential parent DNAs for reproduction will be picked from the current
// population and stored in a selection pool. DNAs with better fitness
// values have a higher chance to be part of the pool.
createSelectionPool();
// In this implementation parents always create two children and the
// size of the next generation is equal to the current population size.
// You can experiment with a variable number of children or let the
// population size increase or decrease over time.
for (size_t iDNA = 0; iDNA < _halfPopulationSize; iDNA++)
{
// SELECTION (See Tutorial)
selectParentsFromPool();
// RECOMBINATION (See Tutorial)
auto child1 = _nextGeneration[iDNA].get();
auto child2 = _nextGeneration[iDNA + _halfPopulationSize].get();
if (getRandomTrueWithProbability(_recombinationProbability))
{
child1->recombineGenes(*_parentDNA1, *_parentDNA2);
child2->recombineGenes(*_parentDNA2, *_parentDNA1);
}
else
{
child1->copyGenes(*_parentDNA1);
child2->copyGenes(*_parentDNA2);
}
// MUTATION (See Tutorial)
child1->mutateGenes(_mutationProbability);
child2->mutateGenes(_mutationProbability);
}
// REPLACEMENT (See Tutorial)
_population.swap(_nextGeneration);
// FITNESS EVALUATION (See Tutorial)
const double previousBestFitness = _bestDNA->getFitness();
calcAllFitnessValues();
// PERFORMANCE STATISTICS
if (_bestDNA->getFitness() < previousBestFitness &&
_objective == GeneticAlgorithmObjective::Minimization)
{
_numGenerationImprovements++;
}
else if (_bestDNA->getFitness() > previousBestFitness &&
_objective == GeneticAlgorithmObjective::Maximization)
{
_numGenerationImprovements++;
}
_numEvolvedGenerations++;
}
template<typename DNA>
inline void GeneticAlgorithm<DNA>::createSelectionPool()
{
// Usual methods for SELECTION in a Genetic Algorithm are:
//
// - Fitness Proportionate Selection
// - Roulette Wheel Selection
// - Stochastic Universal Sampling
// - Rank Selection
// - Elitist Selection
// - Tournament Selection
// - Truncation Selection
//
// This implementation combines some of the ideas.
//
// When a new generation will be evolved, not every DNA in the population
// will get a chance to reproduce. A given percentage of the best DNAs will
// be placed in a pool from which parents will be randomly selected
// for reproduction. A DNA with a better fitness value will be inserted
// more often into the selection pool than a DNA with a low fitness value.
// A DNA which is represented more often in the pool has a higher
// probability to be selected as a parent.
//
// Imagine the selection pool as a roulette wheel. Each DNA in the pool gets
// a slot in a roulette wheel. The size of the slot is based on the fitness
// of the DNA. When selecting parents for reproduction it is like throwing
// two balls into a roulette wheel. The balls have a higher chance of
// landing in bigger slots than in smaller slots.
//
// When a single DNA has a very high fitness value and all other DNAs have
// very low values, the one good DNA will become overrepresented in the
// pool and it will be selected for reproduction nearly every time.
// This (elitism) will reduce the diversity in the next generation and the
// evolution may get stuck very fast. To get a more balanced representation
// of good DNAs in the pool, their relative fitness values (to each other)
// will be used instead of their absolute fitness values. All DNAs of a
// population will be sorted in a list based on their fitness values.
// Their position in the list will define their rank (relative fitness).
// A percentage of the best ranked DNAs will be inserted into the
// selection pool.
//
// The DNAs will not be copied to the ranking list or the selection pool.
// Both are vectors of indices pointing to the DNAs in the population.
// A ranking of DNA indices will be created. The DNAs will be sorted based
// on their fitness values.
vector<pair<size_t, double>> ranking(_populationSize);
for (size_t iDNA = 0; iDNA < _populationSize; iDNA++)
ranking[iDNA] = make_pair(iDNA, _population[iDNA]->getFitness());
if (_objective == GeneticAlgorithmObjective::Minimization)
{
std::sort(
ranking.begin(),
ranking.end(),
[](pair<size_t, double>& left, pair<size_t, double>& right)
{
return left.second < right.second;
});
}
else if (_objective == GeneticAlgorithmObjective::Maximization)
{
std::sort(
ranking.begin(),
ranking.end(),
[](pair<size_t, double>& left, pair<size_t, double>& right)
{
return left.second > right.second;
});
}
// Take some percentage of the best DNAs from the ranking as candidates
// for the selection pool. Better ranked candidates have a higher
// probability to get inserted into the pool.
_selectionPool.clear();
const size_t candidateCount =
static_cast<size_t>( ranking.size() * (_percentOfBestCanReproduce * 0.01) );
const double candidateQuotient = 1.0 / candidateCount;
double insertionProbability = 0.0;
for (size_t rank = 0; rank < candidateCount; rank++)
{
insertionProbability = 1.0 - rank * candidateQuotient;
// Optional: Strong (exponential) falloff
insertionProbability = std::pow(insertionProbability, 2.0);
if (getRandomTrueWithProbability(insertionProbability))
_selectionPool.push_back(ranking[rank].first);
}
}
template<typename DNA>
inline void GeneticAlgorithm<DNA>::selectParentsFromPool()
{
// Randomly select two DNAs from the selection pool.
// DNAs with better fitness values have a higher chance to get selected
// because they have a higher appearance in the selection pool.
// It is tolerable that sometimes both parents will be the same DNA.
const auto poolIdx1 =
getRandomIntegerInRange<size_t>(0, _selectionPool.size() - 1);
const auto poolIdx2 =
getRandomIntegerInRange<size_t>(0, _selectionPool.size() - 1);
const auto dnaIdx1 = _selectionPool[poolIdx1];
const auto dnaIdx2 = _selectionPool[poolIdx2];
_parentDNA1 = _population[dnaIdx1].get();
_parentDNA2 = _population[dnaIdx2].get();
}
// A DNA class implements a particular problem to be solved by a Genetic
// Algorithm. The class manages its own reproduction, mutation and fitness
// evaluation. There is no abstract base class for a DNA to inherit from.
// A user has to implement the class with its particular methods and inject
// it into a Genetic Algorithm by using templates. With this 'duck typing'
// approach there will be no performance overhead by runtime method binding
// (virtual functions). All types will be figured out at compile time.
// This DNA class implements a solution for a Travelling Salesman Problem.
// From the given route locations the shortest possible route should be found.
// The DNA represents a route. The genes of the DNA are the route locations.
// The fitness value of the DNA is defined by the total length of the route.
// In this specific case the objective is to minimize the fitness value.
#pragma once
#include <algorithm>
#include <numeric>
#include <array>
using std::array;
#include <vector>
using std::vector;
#include <string>
using std::string;
#include <cmath>
using std::sqrt;
using std::pow;
#include "randnumgen.hpp"
class DNA_TSP
{
// Methods to be called by the GeneticAlgorithm class:
public:
DNA_TSP(
const vector<double>& routeLocationsX,
const vector<double>& routeLocationsY,
double routeLength = 0.0);
DNA_TSP(const DNA_TSP& copyFrom);
DNA_TSP& operator = (const DNA_TSP& copyFrom);
~DNA_TSP();
void initGenesWithRandomValues();
void copyGenes(const DNA_TSP& copyFrom);
void recombineGenes(const DNA_TSP& parent1, const DNA_TSP& parent2);
void mutateGenes(double probability);
double calcFitness();
double getFitness() const;
string toString() const;
bool isSolved() const;
// Specific methods and properties for a Travelling Salesman Problem:
private:
inline double calcRouteLength(const vector<size_t>& route);
inline double euclidianDistance2D(
double x1,
double y1,
double x2,
double y2);
inline void orderCrossover_OX(const DNA_TSP& dna1, const DNA_TSP& dna2);
inline bool isGeneInSection(
size_t gene,
size_t iSectionStart,
size_t iSectionEnd) const;
inline void swapMutation();
inline void twoOptLocalSearch();
inline void twoOptSwap(
const vector<size_t>& inGenes,
vector<size_t>& outGenes,
size_t iGene1,
size_t iGene2);
private:
const vector<double>* _locationsX;
const vector<double>* _locationsY;
double _routeLength;
vector<size_t> _genes;
double _fitness;
};
#include "dna_tsp.hpp"
DNA_TSP::DNA_TSP(
const vector<double>& routeLocationsX,
const vector<double>& routeLocationsY,
double routeLength)
{
_locationsX = &routeLocationsX;
_locationsY = &routeLocationsY;
_routeLength = routeLength;
// Fill the route with all possible locations. In this case the genes
// are indices for the location coordinates.
_genes.resize(routeLocationsX.size());
std::iota(_genes.begin(), _genes.end(), 0);
// For the Travelling Salesman Problem the fitness value of the DNA
// is represented by the total length of the route, which should be
// minimized. It will be initialized with the worst possible value.
_fitness = std::numeric_limits<double>::max();
}
DNA_TSP::DNA_TSP(const DNA_TSP& copyFrom)
{
_locationsX = copyFrom._locationsX;
_locationsY = copyFrom._locationsY;
_routeLength = copyFrom._routeLength;
_fitness = copyFrom._fitness;
copyGenes(copyFrom);
}
DNA_TSP& DNA_TSP::operator = (const DNA_TSP& copyFrom)
{
_locationsX = copyFrom._locationsX;
_locationsY = copyFrom._locationsY;
_routeLength = copyFrom._routeLength;
_fitness = copyFrom._fitness;
copyGenes(copyFrom);
}
DNA_TSP::~DNA_TSP()
{
}
void DNA_TSP::initGenesWithRandomValues()
{
// Randomly shuffle the genes (route indices).
size_t iGeneSwap = 0;
size_t geneTemp = 0;
for (size_t iGene = 0; iGene < _genes.size(); iGene++)
{
iGeneSwap = getRandomIntegerInRange<size_t>(0, _genes.size() - 1);
geneTemp = _genes[iGene];
_genes[iGene] = _genes[iGeneSwap];
_genes[iGeneSwap] = geneTemp;
}
}
void DNA_TSP::copyGenes(const DNA_TSP& copyFrom)
{
_genes.resize(_locationsX->size());
for (size_t iGene = 0; iGene < _genes.size(); iGene++)
_genes[iGene] = copyFrom._genes[iGene];
}
void DNA_TSP::recombineGenes(
const DNA_TSP& parent1,
const DNA_TSP& parent2)
{
// This DNA will become a child of both parent DNAs by copying some genes
// of parent1 and some genes of parent2. This recombination is also called
// crossover. The following methods are typically used as a
// crossover operator:
//
// - Every gene has a 50% chance to be copied from parent1 and a 50%
// chance to be copied from parent2.
//
// - A fixed or random crossover point (index) will be set.
// All genes before the index will be copied from parent1 and all genes
// after the the index will be copied from parent2. Alternative crossover
// methods may use multiple crossover points to copy different sections
// from parent DNAs.
//
// Both methods can NOT be used for the Travelling Salesman Problem because
// this way some of the genes might be duplicated. The same route location
// (gene) can be inserted from parent1 and parent2 but the Travelling
// Salesman Problem demands that every route location is unique!
//
// There are some special crossover methods for TSP:
//
// - Partially-mapped crossover (PMX)
// - Cycle crossover (CX)
// - Position-based crossover (PBX)
// - Order-based crossover (OBX)
// - Order crossover (OX)
//
// One of the best methods is the order crossover (OX) which is used here.
orderCrossover_OX(parent1, parent2);
}
void DNA_TSP::mutateGenes(double probability)
{
// The DNA will be mutated by picking a single gene (point mutation) or
// multiple genes (with a given rate / probability) and exchange them
// with new genes from the set of all possible genes.
//
// This method can NOT be used for the Travelling Salesman Problem because
// this way some of the genes will be duplicated. The same route location
// may get inserted multiple times into the DNA but the Travelling Salesman
// Problem demands that every route location is unique!
//
// Two of many possible solutions to solve this problem are:
// 1) Pick one random gene in the DNA and swap it with its next neighbor.
// 2) Pick two random genes in the DNA and swap them.
// We are going to use the latter with a given probability:
if (getRandomTrueWithProbability(probability))
swapMutation();
// OPTIONAL:
// There are specialized heuristics like the 2-opt local search algorithm
// which tries to find better solutions for the Travelling Salesman Problem
// by reordering the route locations when the route crosses over itself.
// A Genetic Algorithm will find a global optimum solution much faster
// when a local search algorithm will be used after the mutation.
twoOptLocalSearch();
// When 2-opt search is used the population size can / should be very low!
// Recommended parameters for the Genetic Algorithm when 2-opt is used:
// populationCount = 100;
// percentOfBestCanReproduce = 50.0;
// recombinationProbability = 0.9;
// mutationProbability = 0.02;
// When 2-opt search is NOT used the population size has to be much higher!
// Recommended parameters for the Genetic Algorithm when 2-opt is NOT used:
// populationCount = 150000;
// percentOfBestCanReproduce = 10.0;
// recombinationProbability = 0.9;
// mutationProbability = 0.02;
}
double DNA_TSP::calcFitness()
{
// FITNESS FUNCTION
// The fitness value of the DNA is defined by the total length of the
// route. In this case of a Travelling Salesman Problem the objective
// is to minimize the fitness value.
_fitness = calcRouteLength(_genes);
// To get a better separation of different DNAs with a similar fitness,
// the values can be squared to get exponential instead of linear results
// (_fitness = _fitness * _fitness). Squared fitness values are not
// beneficial in this case because the GeneticAlgorithm class uses a
// rank based selection method for DNAs which sorts all fitness values.
return _fitness;
}
double DNA_TSP::getFitness() const
{
return _fitness;
}
string DNA_TSP::toString() const
{
// This returns a string of all route locations which are represented
// as indices of the coordinate arrays. The route is a loop and will be
// shifted to always display index 0 as the first route location.
//
// The standard string has a move constructor, so returning long strings
// by value is efficient.
// Find the start of the route.
size_t iRouteStart = 0;
for (size_t iGene = 0; iGene < _genes.size(); iGene++)
if (_genes[iGene] == 0)
{
iRouteStart = iGene;
break;
}
// Get the elements from the route start index to the end of the array.
string dnaStr = "[";
for (size_t iGene = iRouteStart; iGene < _genes.size(); iGene++)
{
if (_genes[iGene] < 10)
dnaStr += " ";
dnaStr += std::to_string(_genes[iGene]) + ", ";
}
// Get the elements from the start of the array to the route start index.
for (size_t iGene = 0; iGene < iRouteStart; iGene++)
{
if (_genes[iGene] < 10)
dnaStr += " ";
dnaStr += std::to_string(_genes[iGene]) + ", ";
}
return dnaStr + "]";
}
bool DNA_TSP::isSolved() const
{
return _fitness < _routeLength;
}
inline double DNA_TSP::calcRouteLength(const vector<size_t>& route)
{
// This calculates the sum of all distances between successive
// route locations.
double totalLength = 0.0;
for (size_t i = 0; i < route.size() - 1; i++)
totalLength += euclidianDistance2D(
_locationsX->at(route[i]),
_locationsY->at(route[i]),
_locationsX->at(route[i + 1]),
_locationsY->at(route[i + 1]));
// Add the distance from the last to the first route location.
totalLength += euclidianDistance2D(
_locationsX->at(route[route.size() - 1]),
_locationsY->at(route[route.size() - 1]),
_locationsX->at(route[0]),
_locationsY->at(route[0]));
return totalLength;
}
inline double DNA_TSP::euclidianDistance2D(
double x1,
double y1,
double x2,
double y2)
{
return sqrt( pow(x1 - x2, 2.0) + pow(y1 - y2, 2.0) );
}
inline void DNA_TSP::orderCrossover_OX(
const DNA_TSP& dna1,
const DNA_TSP& dna2)
{
// This crossover method will copy the genes of two parent DNAs
// without creating any duplicates and by preserving their order.
// The result will be a valid route for the Travelling Salesman Problem.
//
// A section of genes from dna1 will be copied to this dna and the
// remaining genes will be copied to this dna in the order in which they
// appear in dna2.
// Get a random start and end index for a section of dna1.
size_t iSecStart = 0;
size_t iSecEnd = 0;
while (iSecStart >= iSecEnd)
{
iSecStart = getRandomIntegerInRange<size_t>(0, dna1._genes.size() - 1);
iSecEnd = getRandomIntegerInRange<size_t>(0, dna1._genes.size() - 1);
}
// Copy the section of dna1 to this dna.
for (size_t iGene = iSecStart; iGene <= iSecEnd; iGene++)
_genes[iGene] = dna1._genes[iGene];
const size_t sectionSize = iSecEnd - iSecStart;
// Copy the genes of dna2 without the genes found in the section of dna1.
// The copying begins after the end index of the section. When the end of
// dna2 is reached, copy the genes from the beginning of dna2 to the start
// index of the section.
vector<size_t> dnaDifference;
dnaDifference.reserve(dna2._genes.size() - sectionSize);
if (iSecEnd + 1 <= dna2._genes.size() - 1)
for (size_t iGene = iSecEnd + 1; iGene < dna2._genes.size(); iGene++)
if (!isGeneInSection(dna2._genes[iGene], iSecStart, iSecEnd))
dnaDifference.push_back(dna2._genes[iGene]);
for (size_t iGene = 0; iGene <= iSecEnd; iGene++)
if (!isGeneInSection(dna2._genes[iGene], iSecStart, iSecEnd))
dnaDifference.push_back(dna2._genes[iGene]);
// The difference from dna1 and dna2 will be copied to this dna.
// The insertion of genes into this dna begins after the end index of the
// section. When the end of the dna is reached, insert the genes in the
// beginning of the dna to the start index of the section.
size_t i = 0;
if (iSecEnd + 1 <= dna2._genes.size() - 1)
i = iSecEnd + 1;
for (size_t iGene = 0; iGene < dnaDifference.size(); iGene++)
{
_genes[i] = dnaDifference[iGene];
i++;
if (i > _genes.size() - 1)
i = 0;
}
}
inline bool DNA_TSP::isGeneInSection(
size_t gene,
size_t iSectionStart,
size_t iSectionEnd) const
{
for (size_t iGene = iSectionStart; iGene <= iSectionEnd; iGene++)
if (gene == _genes[iGene])
return true;
return false;
}
inline void DNA_TSP::swapMutation()
{
// This mutates the DNA in a minimal way by selecting two random genes
// and swapping them with each other.
const auto iGene1 = getRandomIntegerInRange<size_t>(0, _genes.size() - 1);
const auto iGene2 = getRandomIntegerInRange<size_t>(0, _genes.size() - 1);
const auto tempGene = _genes[iGene1];
_genes[iGene1] = _genes[iGene2];
_genes[iGene2] = tempGene;
}
inline void DNA_TSP::twoOptLocalSearch()
{
// '2-opt' is a local search algorithm for optimizing a Travelling Salesman
// Problem. It takes a route that crosses over itself and reorders the
// locations to eliminate the cross over.
// The reordering will be applied to all possible location pairs as long as
// it can improve the total length of the route.
bool hasImproved = true;
double swappedGenesFitness = 0.0;
vector<size_t> swappedGenes(_genes.size());
while (hasImproved)
{
for (size_t iGene1 = 1; iGene1 < _genes.size() - 1; iGene1++)
for (size_t iGene2 = iGene1 + 1; iGene2 < _genes.size(); iGene2++)
{
twoOptSwap(_genes, swappedGenes, iGene1, iGene2);
swappedGenesFitness = calcRouteLength(swappedGenes);
if (swappedGenesFitness < _fitness)
{
_genes.swap(swappedGenes);
_fitness = swappedGenesFitness;
hasImproved = true;
}
else { hasImproved = false; }
}
}
}
inline void DNA_TSP::twoOptSwap(
const vector<size_t>& inGenes,
vector<size_t>& outGenes,
size_t iGene1,
size_t iGene2)
{
// Take inGenes[0] to inGenes[iGene1 - 1]
// and add them in order to outGenes
for (size_t iGene = 0; iGene <= iGene1 - 1; iGene++)
outGenes[iGene] = inGenes[iGene];
// Take inGenes[iGene1] to inGenes[iGene2] and
// add them in reverse order to outGenes
size_t iter = 0;
for (size_t iGene = iGene1; iGene <= iGene2; iGene++)
{
outGenes[iGene] = inGenes[iGene2 - iter];
iter++;
}
// Take inGenes[iGene2 + 1] to end of inGenes
// and add them in order to outGenes
for (size_t iGene = iGene2 + 1; iGene < inGenes.size(); iGene++)
outGenes[iGene] = inGenes[iGene];
}